

Introduction
Les Regex ou expressions régulières servent à :
- Vérifier qu’un champ rentré par un utilisateur ressemble au champ demandé (match)
- Reformater un champ utilisateur afin qu’il réponde au champ demandé (replace)
Info : En PHP, toutes les fonctions dédiées aux Regex sont préfixées par « preg« . Exemple : preg_match(), preg_replace().
Pour créer des Regex, j’utilise le site Regex101.com. On y trouve un IDE spécialisé dans les Regex avec des explications en temps réel sur ce que l’on saisit à l’écran, un moyen de tester notre Regex et un bouton pour générer notre code en PHP.
L’Email, un exemple type
L’exemple type est un email. L’email est composé de :
- [caractères alphanumériques, de tirets, de points]
- [suivi d’un @]
- [d’un nom de domaine ou, plus compliqué, d’un sous-nom de domaine]
- [d’un point]
- [de l’extension représentant le pays : fr, jp, it, es,… ou le type d’entité : com, org,…]
Il est important dans un Regex de récupérer tout ce qui représente le champ de façon atomique (non divisible).
Le n°3 contenant le nom de domaine ne contient pas le pays ou le point. Par exemple : pour l’entreprise Google, on trouve gmail.com, gmail.fr, etc.
Pour gmail.fr :
3. [gmail] = il est chez gmail, on pourra demander à la personne de donner un avis sur Google.
4. [le point]
5. [fr] = il est français. C’est utile et permet de ne pas lui demander son pays.
L’interface de regex101.com
La partie où on écrit notre Regex

La partie juste en dessous où on teste le Regex en saisissant un email, par exemple
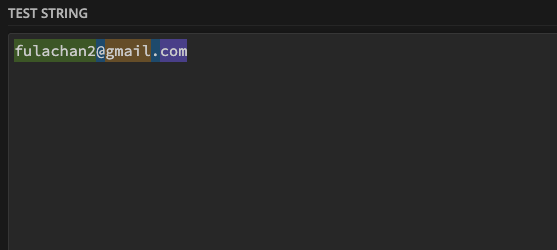
La partie à droite donne les explications en temps réel sur le Regex saisi.
Pour finir, sous les explications, on trouve la notice pour créer un Regex.
Parlons technique…
Basé sur cet email : monnom-74@fai.fr
Sélecteurs de caractères
Par exemple, é:,eré@:frt.fr n’est pas un email valide. Pourquoi ? Cela contient des caractères interdits dans un email ( é ; : )
Je vérifie qu’avant le » @ « , on puisse entrer des lettres de « a » à « z » et des chiffres de « 0 » à « 9 » ainsi que des » – » et des » . « . C’est parti et cela se met entre crochets.
[abcdefghijklmnopqrstuvwxyz0123456789\.\ \-] c’est super long, mais il existe plus court [a-z0-9\.\ \-] On remarque que pour le point, je mets un antislash devant. Il s’agit d’un caractère d’échappement afin d’utiliser ce point non pas comme un caractère réservé au code, mais bien comme un point. Pour information : le point signifie tous les caractères. Exemple [.]
À propos de caractères réservés, on peut mettre un ^ en début de sélecteur afin de créer une négation.
Exemple, je veux tous les caractères sauf é à è ç ù ê ë. Cela donne : [^éàèçùêë]
Ou ne pas mettre de chiffres : [^0-9]
Parmi les sélecteurs, des écritures encore plus courtes existent comme les classes de caractères. Exemple avec [0-9] pour les caractères numériques qui équivaut à :
\d (sans crochets)
[[:digit:]] (classe de caractères)
Quantificateur de caractères
Ok, [a-z0-9] c’est bien, mais cela m’autorise à ne mettre aucun caractère et dans un email, c’est compliqué.
J’aimerais en mettre au minimum 3 et pas de maximum. On écrit donc : [a-z0-9]{3,}
Et puis en fait, j’en veux 3 précisément (ni plus, ni moins). On écrit donc : [a-z0-9]{3}
Et puis en fait, j’en veux au minimum 3 et 20 maximum. On écrit donc : [a-z0-9]{3,20}
Et si je veux aucune limite. On écrit donc: [a-z0-9]*
On continue notre Regex…
Il nous faut « @fai.fr« , cela donne:
[@]{1} Il n’y a qu’un seul @ dans un email
[a-z0-9\-]{2,20} Dans un nom de domaine, on imagine qu’il y a des chiffres, des lettres et un tiret et que sa longueur soit de 2 caractères au moins avec une limite
[\.]{1} Il y a un point après le nom de domaine dans un email.
[a-z]{2,4} Et pour finir, l’extension doit avoir au minimum 2 caractères (ex : fr) mais pas forcément bien plus.
On a fini notre Regex, il reste plus qu’à l’assembler. Un Regex se met entre 2 délimiteurs. Par exemple des slashs.
/ MON REGEX / Options de Regex (multiligne, global, etc…)
C’est parti !
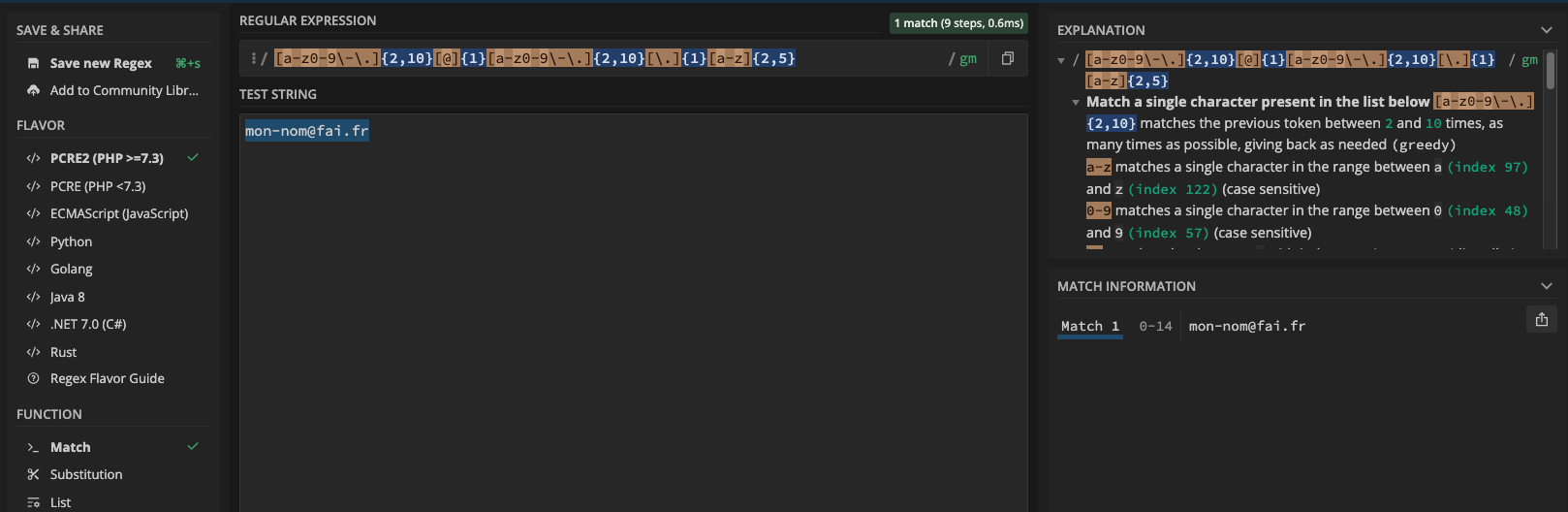
On remarque que le test est surligné en bleu. Cela signifie que cela « Match ». On remarque que sur la gauche la « Function » est « Match ».
Ce mode de vérification est utilisé lorsqu’un utilisateur renseigne son email dans un formulaire de contact. Une condition PHP vérifie le bon format de l’email via le Regex. En code, cela donne :
$regex = '/[a-z0-9\-\.]{2,10}[@]{1}[a-z0-9\-\.]{2,10}[\.]{1}[a-z]{2,5}/m';
$email = 'mon-nom@fai.fr';
if(preg_match($regex, $email)){
echo "Email OK";
}
Les groupes de capture
À ce stade, ce qui serait intéressant, c’est d’utiliser le nom de domaine pour renvoyer une phrase plus personnalisée. Exemple avec mon-nom@free.fr et une réponse qui dit : « Cool, tu es chez Free ? »
Pour faire cela, on va utiliser les groupes. On va faire des groupes de cette façon (voir code couleur) :
[a-z0-9]{3,20}[@]{1}[a-z0-9\-]{2,20}[\.]{1}[a-z]{2,4}
et pour faire des groupes on utilise des parenthèses. Cela transforme notre Regex ainsi :
([a-z0-9]{3,20}) ([@]{1}) ([a-z0-9\-]{2,20}) ([\.]{1}) ([a-z]{2,4})
Sur l’interface de Regex101.com on remarque une différence sur « Match information »
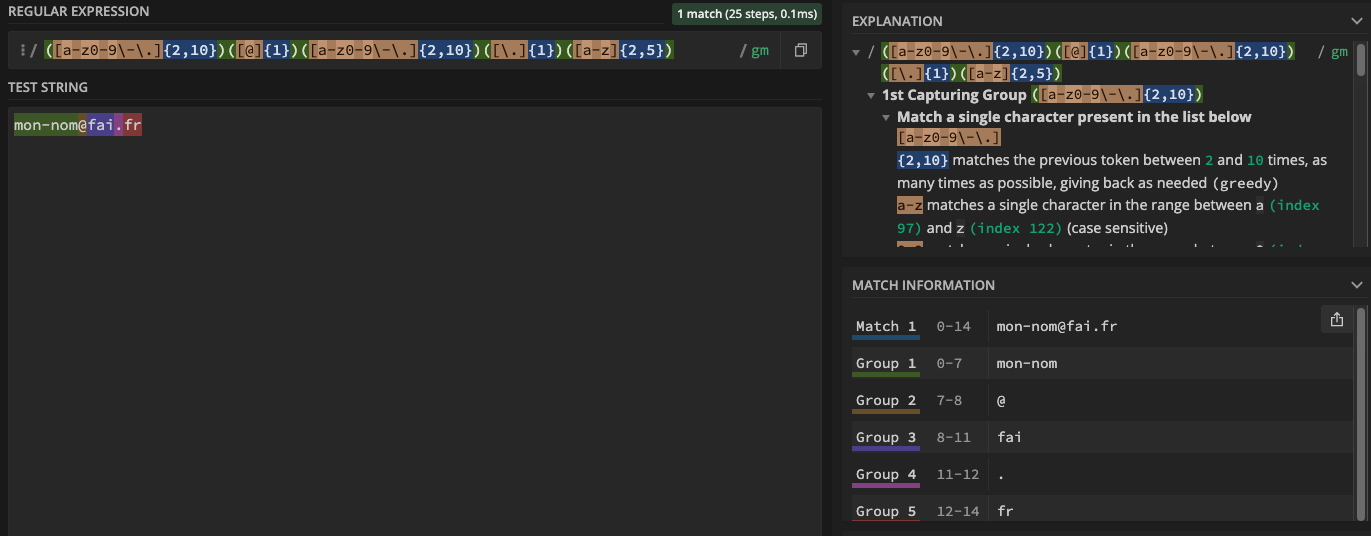
Testons ce code :
$regex = '/([a-z0-9\-\.]{2,10})([@]{1})([a-z0-9\-\.]{2,10})([\.]{1})([a-z]{2,5})/m';
$string = 'mon-nom@fai.fr';
preg_match_all($regex, $string, $nosGroupes);
// Print the entire match result
var_dump($nosGroupes);
On récupère dans la variable $nosGroupes un tableau avec tous les groupes capturés individuellement.
Pour récupérer le FAI, on entre : var_dump($nosGroupes[3][0]);
Des « Match » au « Replace »
Il existe un mode plus adapté encore qui peut être mixé au « Match », il s’agit du mode « replace » ou de substitution.
Prenons un exemple. J’ai un numéro de téléphone qui ressemble à ceci 0674009006 ou a ceci 06/74-00/9006 et je souhaite qu’il soit formaté ainsi dans ma base de données 06 74 00 90 06
C’est plus classe, n’est-ce pas ?
Pour ce faire on va faire des groupes de 2 nombres sous forme de groupe donc entre parenthèses et entre eux, un autre groupe qui acceptera des caractères:
« -« , » / « , » . « , espace ou rien
On va aussi régler notre IDE en ligne regex101.com sur « Substitution« .
On verra un encart « Substitution » apparaître en bas.
Les groupes de substitutions
Je récupère tous les groupes = $0
Je récupère le groupe 1 = $1
Je récupère le groupe 2 = $2
etc…. (Voir « match information« )
Dans le cas où je ne souhaiterais pas récupérer (on dit « capturer ») un groupe, devant la paranthèse entrante j’écris ?:
Ce qui donne :
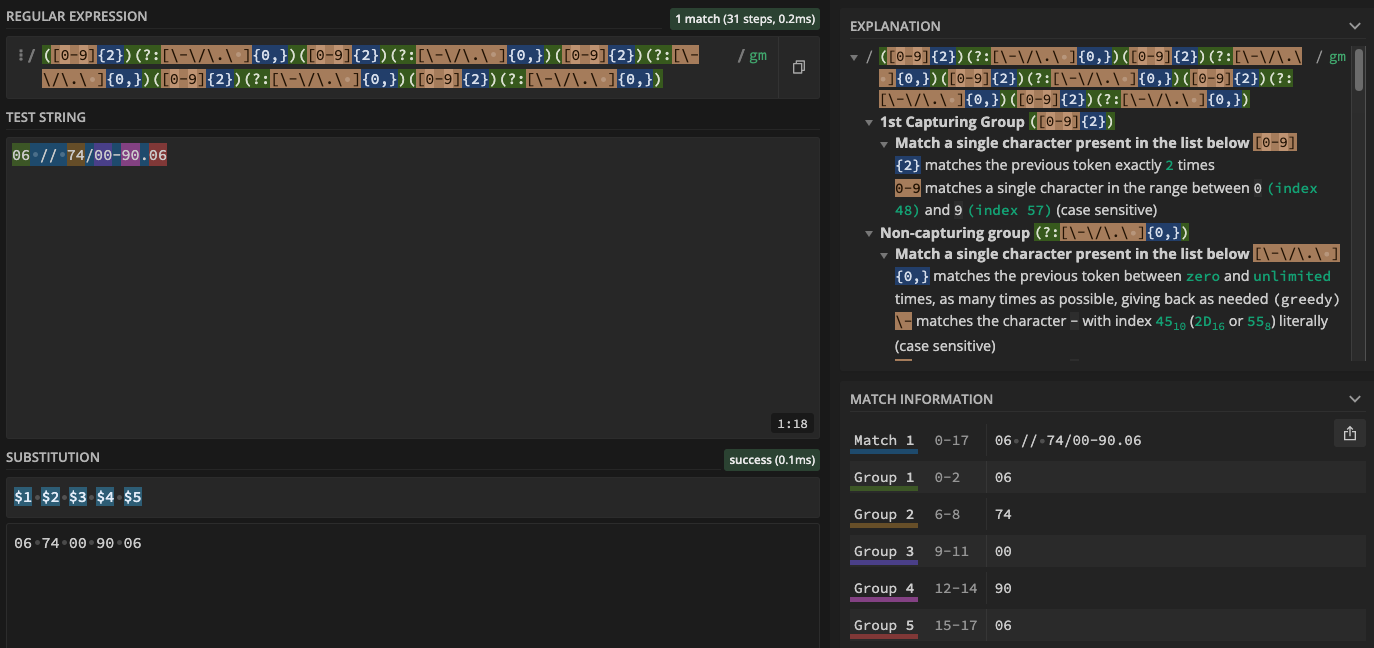
On a donc, grâce à la ‘Substitution’, créé un numéro de téléphone reformaté proprement.
Greedy et Ungreedy? Qu’est ce que c’est?
Pour finir….
^ = mon entrée utilisateur a vérifier commence par…
$ = mon entrée utilisateur à vérifier ce fini par…
| = ca ou ca. Exemple pour sélectionner bonjour ou bonsoir: ^bon(jour|soir)$ A ce sujet, entre ^bon(jour|soir)$ et^(bonjour|bonsoir)$, mieux vaut utiliser^bon(jour|soir)$
Pour aller plus loin
Il y a des fonctions telles que les lookahead & Lookbehind permettant de sélectionner une zone d’un texte s’il est précédé ou suivi d’une valeur donnée.
Des classes de caractères permettant de sélectionner des valeurs Hexadécimales, etc…